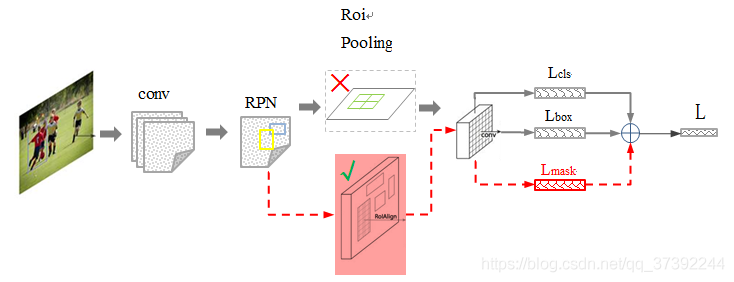
在 Faster R-CNN 的基础上,将 RoI Pooling 换成了 RoI align,并且添加了 Lmask(也是一个 FCN,applied to each RoI)
从 object detection 扩展到了 segmentation
Mask R-CNN·
首先回顾一下 Faster R-CNN,它包含两个阶段,第一阶段是 RPN,to propose candidate object bounding boxes
第二阶段是 Fast R-CNN,通过 RoIPooling 提取相同大小的特征,做 classification 和 bounding-box regression
Mask R-CNN 的第一阶段是一样的,第二阶段加了一个 binary mask for each RoI
L=Lcls+Lbox+Lmask
前两个 loss 跟之前一样
mask 的输出大小是 Km2,K 是分类的数量,m 是 resolution,Lmask 是首先做一个 per-pixel sigmoid 然后 loss 是 average binary cross-entropy loss,对于 ground-truth 分类是 k 的 RoI,只关心 k 这一类的预测的 mask
mask 的 predicion 用的是全卷积网络,不用什么 fc 层,不会使空间信息受损
这要求 RoI features to faithfully preserve the explicit per-pixel spatial correspondence,因此提出 RoI Align
RoI Align·
RoI Pooling 用到了太多的 quantization:首先将所有的浮点数取整,然后根据输出大小分块,每一块做 max pool,分块的时候显然也得用取整来确定大小,这对于分割影响很大:有的 feature 点对应一个像素,有的对应两个,这就无法准确地还原对应位置
These quantizations introduce misalignments between the RoI and the extracted features.

就很暴力地不用任何取整
用双线性插值:它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
如下图所示,蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
