- construct feature pyramids with 最低的 extra cost
- 为了解决不同尺度下的 object detection 问题
- 卷积层自带不同尺寸的功能,每卷一层尺寸缩小一点,并且 semantically stronger
Feature Pyramid Networks·
输入一张任意大小的图片,输出不同比例缩放下的不同大小的 feature map
independent of the backbone convolutional architectures
a bottom-up pathway, a top-down pathway, and lateral connections
bottom-up pathway·
backbone ConvNet 的 feed-forward computation
正常的卷积网络可以根据输出的大小分成很多 stage,有的卷积层输入跟输出一样大小,有的可能降低尺寸。我们把输出一样尺寸的一段称为一个 stage,并且只关心每个 stage 的最后一层的输出。用它们生成我们的金字塔。
top-down pathway and lateral connections·
从上往下,把上面的 小的 语义信息浓度高的 层 unsample 到下一层去,让下一层有更多的语义信息

横向连接做 1×1 的卷积是为了降低 channel 的数量
对于每一个 merged map,我们加上一个 3×3 的卷积,to reduce the aliasing effect of unsampling(混叠效应)
FPN应用于RPN·
Faster RCNN中的RPN是通过最后一层的特征来做的。最后一层的特征经过3x3卷积,得到256个channel的卷积层,再分别经过两个1x1卷积得到类别得分和边框回归结果。这里将特征层之后的RPN子网络称之为网络头部(network head)。对于特征层上的每一个点,作者用anchor的方式预设了9个框。这些框本身包含不同的尺度和不同的长宽比例。
FPN针对RPN的改进是将网络头部应用到每一个P层。由于每个P层相对于原始图片具有不同的尺度信息,因此作者将原始RPN中的尺度信息分离,让每个P层只处理单一的尺度信息。具体的,对{322、642、1282、2562、5122}这五种尺度的anchor,分别对应到{P2、P3、P4、P5、P6}这五个特征层上。每个特征层都处理1:1<spanclass="bd−box"><h−charclass="bdbd−beg"><h−inner>、</h−inner></h−char></span>1:2<spanclass="bd−box"><h−charclass="bdbd−beg"><h−inner>、</h−inner></h−char></span>2:1三种长宽比例的候选框。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
另外,上述5个网络头部的参数是共享的。作者通过实验发现,网络头部参数共享和不共享两种设置得到的结果几乎没有差别。这说明不同层级之间的特征有相似的语义层次。这和特征金字塔网络的原理一致。
FPN应用于Fast RCNN·
作者将FPN的各个特征层类比为图像金字塔的各个level的特征,从而将不同尺度的RoI映射到对应的特征层上。以224大小的图片输入为例,宽高为w和h的RoI将被映射到的特征级别为k,它的计算公式如下:
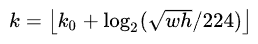
在ResNet中,k0的值为4,对应了长宽为224的框所在的层次。如果框的长宽相对于224分别除以2,那么k的值将减1,以此类推。
在Faster RCNN中,ResNet的conv4层被用来提取RoI,经过RoI Pooling后映射到14x14的大小。经过RoI Pooling后的特征再进入原来的conv5层,进而得到最终的分类和边框回归结果。在FPN中,conv5层已经被用来作为特征提取器得到P5层;因此,这里单独设计两个1024维的全连接层作为检测网络的网络头部。新的网络头部是随机初始化的,它相比于原来的conv5层更加轻量级。