Lecture 2·
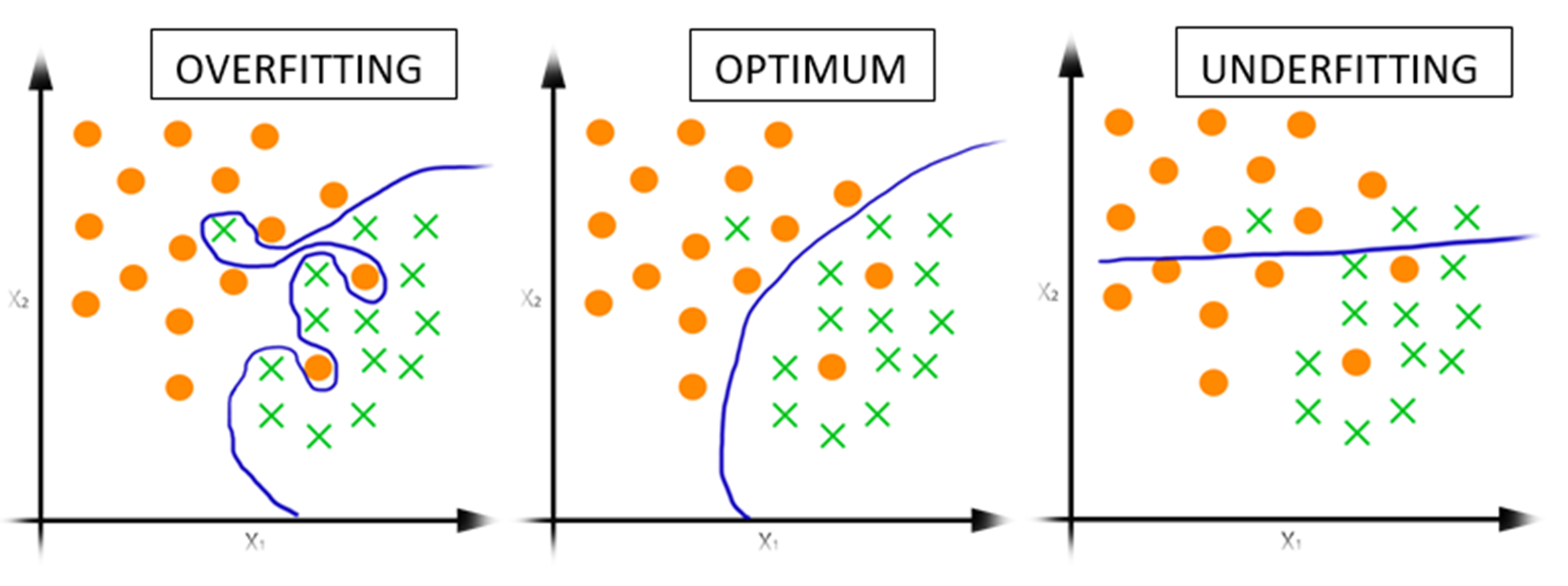
overfit·
- 应对 overfit: restrict the representation power -> “regularization”
- modern view: overfit 并不是问题,在 SGD 中天生的就会有 implicit regularization 来减少 overfit 的可能
Unsupervised Learning·
- clustering
- PCA
- generative model
- anomaly detection
- dimension reduction (PCA application)
Semi-supervised Learning·
Lecture 3·
Optimization·
- zero-order method
- only knows f(x)
- hyperparameter tuning
- first-order method
- knows f(x),f′(x)
- second-order method
- knows f(x),f′(x),f′′(x)
- Hessian matrix is of size O(d2) , d denotes the number of parameters
- 太费时间
Gradient descent·
wt+1=wt−η∇L(wt)
- Smoothness assumption: ∥f′′(w)∥≤L
什么叫 smoothness: 梯度函数是 L-Lipschitz 的,即
∥∇f(x)−∇f(y)∥≤L∥x−y∥.
梯度不会剧烈变化,就说明每一步的梯度下降的步长都比较稳定。
- Lemma: f′(w) 是 L-Lipschitz 当且仅当 ∥f′′(w)∥≤L,∀w∈Rn
Proof
若 ∥f′′(w)∥≤L,有
∥f′(y)−f′(x)∥=(∫01f′′(x+τ(y−x))dτ)⋅(y−x)≤L∥y−x∥
若 ∥f′(y)−f′(x)∥≤L∥y−x∥,有
(∫0αf′′(x+τs)dτ)⋅s=∥f′(x+αs)−f′(x)∥≤αL∥s∥.
两边除掉 α 并令 α→0 就有 ∥f′′(x)∥≤L.
就是对于每个 x 考虑 x 周围 δ 的邻域
- Lemma: f′(w) 是 L-Lipschitz 时,有
∣f(y)−f(x)−⟨f′(x),y−x⟩∣≤2L∥y−x∥2.
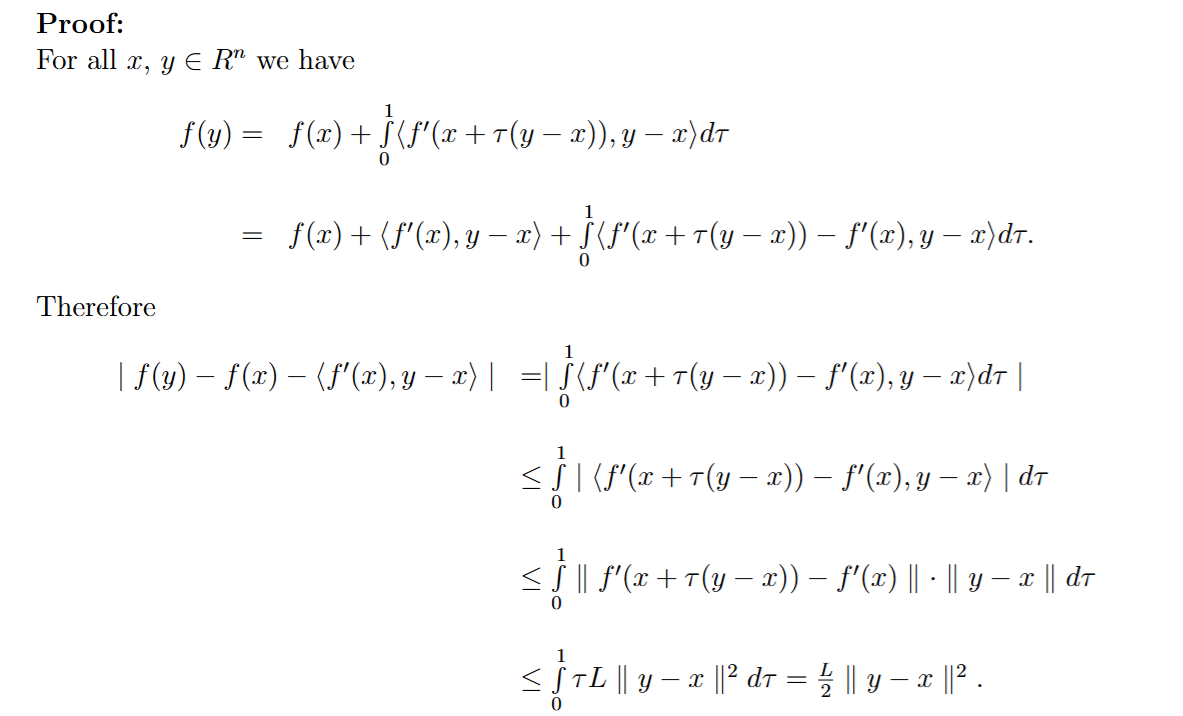
- 当满足梯度光滑条件时,考虑学习率 η 的合适取值范围
我们有 w′=w−ηf′(w),
f(w′)−f(w)≤⟨f′(w),w′−w⟩+2L∥w′−w∥2=−η∥f′(w)∥2+2η2L∥f′(w)∥2=−η(1−2ηL)∥f′(w)∥2
我们希望每一次更新都有 f(w′)−f(w)<0,这需要 η<L2.
这意味着如果函数 f 的梯度平滑,那么梯度下降的效果有很好的保证。