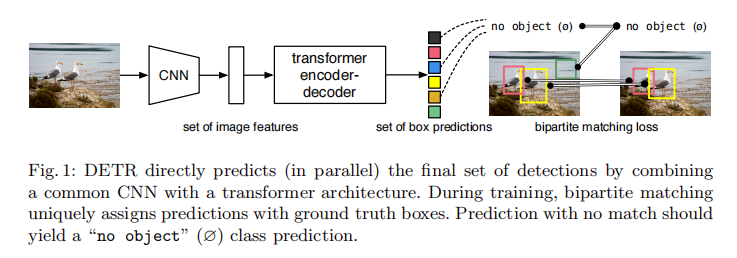
Introduction·
- predict all objects at once
- bipartite matching between predicted and ground-truth objects
- 抛弃了许多之前的技巧
,
The DETR model·
- a set prediction loss that forces unique matching between predicted and ground truth boxes
- an architecture that predicts a set of objects and models their relation
Object detection set prediction loss·
in a single pass, infers a fixed-size of predictions
是一个预设的较大的数
假设 是所有的 ground truth objects
Find a permutation with the lowest cost:
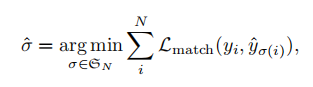
用匈牙利做二分匹配可以快速得到
: 每个 ground truth 和 prediction 都可以视为 其中 是分类
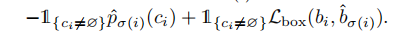
最终的loss如下
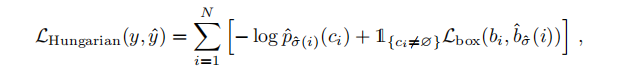
architecture·
Backbone·
从初始图片 做 CNN 提取特征
Transformer encoder·
首先做一个 的卷积
直接摊平成一维
multi-head self-attention
Transformer decoder·
transform embeddings of size