Grading·
- HW 15%
- Coding 40%
- Project 25%
- Final 20%
- Note 8%
Overview·
McCulloch-Pitts Neuron·
Hebbian Learning·
- is the weight between and
The Perceptron·
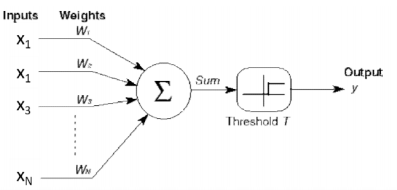
- If then else
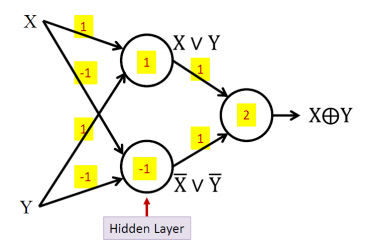
Multi-layer Perceptron·
- can compose arbitrarily complicated Boolean functions
Training a 3-node neural network is NPC.
The first AI Winter·
- The perceptron cannot represent XOR.
- NP-complete
- Funding cuts
Differentiable Functions·
- now have gradient, update weights by back-propagation
Supervised Learning(1)·
analytical solution·
- Consider
- solve
- calculate and verify 是否正定
Iterative solution·
-
Start with a guess
-
iteratively refine until is reached
-
follow the gradient direction
-
Multi-class
-
softmax function
-
-
is often called a logit (refer to an unscaled value)
-
error function: NLL loss (negative log-likelihood loss)
-
-
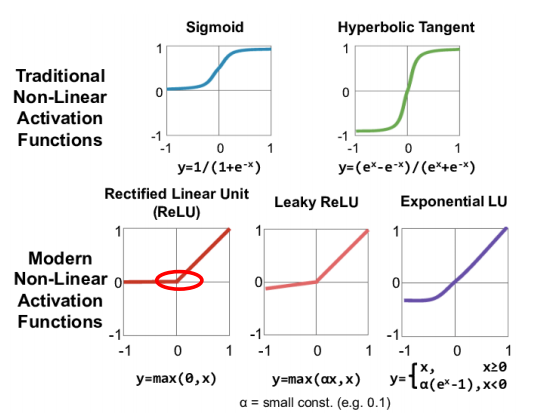
Issues with sigmoid function
- always non-negative
- Alternative:
- Gradient vanishing
- Alternative:
- always non-negative
-
-
Regularization
- L2 norm on all the weights
- 不让 变得太大防止 overfit
- This is also called weight decay
Scanning MLP·
-
scan 整个图像 or 音频 之类的
, -
相当于识别 local 的 pattern 不管在什么位置
-
Effective in any situation where the data are expected to be composed of similar structures at different locations
- Eg. speech recognition, image recognition
-
loss 就是 每个区域的 loss 的和
-
CNN
- Terminology:
- Filters: scans for a pattern on the map from the previous layer
- Receptive Fields: corresponding patch in the input image
- Strides: the scanning ‘hops’ for each filter
- Padding
- zero padding 是 在外面 pad 0
,
- Fully convolutional network:
- Downsample instead of pooling
- Convolution with stride > 1 to reduce the size
- Equivalent to learn a pooling operator
- Terminology:
Supervised Learning(2)·
https://cloud.tsinghua.edu.cn/f/4eb80bdf09cc42c19ffd/